Avantages et inconvénients des automates finis : instructions switch-case, pointeurs C/C++ et tables de consultation (partie II)
Voici la deuxième et dernière partie de notre implémentation de machine à états finis (MEF). Vous pouvez consulter la première partie de cette série et en apprendre davantage sur les machines à états finis ici.
Les automates à états finis (AEF) sont simplement des calculs mathématiques de causes et d'événements. En fonction de leurs états, un AEF calcule une série d'événements selon l'état de ses entrées. Par exemple, pour un état appelé LECTURE_CAPTEUR , un AEF peut déclencher un relais (ou événement de contrôle) ou envoyer une alerte externe si la valeur lue par un capteur dépasse un seuil prédéfini. Les états constituent l'ADN de l'AEF : ils dictent son comportement interne et ses interactions avec l'environnement, comme la réception d'entrées ou la production de sorties, ce qui peut entraîner un changement d'état du système. En tant qu'ingénieurs matériels, il nous incombe de choisir les états et les événements déclencheurs appropriés pour obtenir le comportement souhaité, adapté aux besoins de notre projet.
Dans la première partie de ce tutoriel sur les automates à états finis (AEF), nous avons créé un AEF à l'aide de l'implémentation classique par instruction switch-case. Nous allons maintenant explorer la création d'un AEF utilisant des pointeurs C/C++, ce qui vous permettra de développer une application plus robuste et de simplifier la maintenance du firmware.
REMARQUE : Le code utilisé dans ce tutoriel a été présenté lors de l’Arduino Day 2018 à Bogota par José Garcia, ingénieur matériel chez Ubidots . Vous trouverez l’intégralité des exemples de code et les notes de présentation ici.
Inconvénients de l'utilisation de Switch-Case :
Dans la première partie de notre tutoriel sur les automates à états finis, nous avons abordé les instructions switch-case et la mise en œuvre d'une routine simple. Nous allons maintenant approfondir ce concept en introduisant les pointeurs et leur utilisation pour simplifier votre routine d'automate à états finis.
Une de type switch-case est très similaire à une if-else ; notre firmware parcourt chaque cas, les évaluant pour déterminer si la condition de déclenchement est atteinte. Voici un exemple de routine :
switch(state) { case 1: /* effectuer des opérations pour l'état 1 */ state = 2; break; case 2: /* effectuer des opérations pour l'état 2 */ state = 3; break; case 3: /* effectuer des opérations pour l'état 3 */ state = 1; break; default: /* effectuer des opérations par défaut */ state = 1; }
Dans le code ci-dessus, vous trouverez un automate fini simple à trois états. Dans la boucle infinie, le firmware passe au premier cas, vérifiant si la variable d'état vaut un. Si c'est le cas, il exécute sa routine ; sinon, il passe au cas 2 où il vérifie à nouveau la valeur de l'état. Si le cas 2 n'est toujours pas satisfait, l'exécution du code se poursuit avec le cas 3, et ainsi de suite jusqu'à ce que l'état soit atteint ou que tous les cas aient été traités.
Avant de nous pencher sur le code, examinons de plus près certains inconvénients potentiels des switch-case ou if-else afin de voir comment améliorer le développement de notre firmware.
Supposons que la variable d'état initiale soit égale à 3 : notre firmware devra effectuer 3 validations de valeur différentes. Cela ne pose généralement pas de problème pour un automate fini, mais imaginez une machine de production industrielle classique comportant des centaines, voire des milliers d'états. La routine devra effectuer plusieurs vérifications de valeur inutiles, ce qui entraînera une utilisation inefficace des ressources. Cette inefficacité constitue notre premier inconvénient : le microcontrôleur, aux ressources limitées, sera surchargé par des routines d'automate fini inefficaces. Il est donc de notre devoir, en tant qu'ingénieurs, d'économiser au maximum les ressources de calcul du microcontrôleur.
Imaginez maintenant un automate fini à états finis (AFM) comportant des milliers d'états : si vous êtes un développeur débutant et que vous devez modifier l'un de ces états, vous devrez examiner des milliers de lignes de code dans votre boucle principale `loop()`. Cette boucle contient souvent beaucoup de code non lié à l'automate lui-même ; il peut donc être difficile de déboguer si toute la logique de l'AFM est concentrée dans la boucle principale `loop()`.
Enfin, un code comportant des milliers d' if-else ou switch-case n'est ni élégant ni lisible pour la majorité des programmeurs de systèmes embarqués.
Pointeurs C/C++
Voyons maintenant comment implémenter un automate fini concis à l'aide de pointeurs en C/C++. Un pointeur, comme son nom l'indique, désigne une zone mémoire du microcontrôleur. En C/C++, un pointeur pointe vers une adresse mémoire afin d'en récupérer une information. Un pointeur permet d'accéder à la valeur stockée d'une variable pendant l'exécution, sans connaître son adresse mémoire. Correctement utilisés, les pointeurs peuvent considérablement simplifier la structure de votre programme et faciliter sa maintenance et son édition ultérieures.
- Exemple de code de point :
int a = 1462; int myAddressPointer = &a; int myAddressValue = *myAddressPointer;
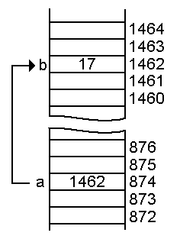
Analysons le code ci-dessus. La variable `myAddressPointer` pointe vers l'adresse mémoire de la variable `a` (1462), tandis que la variable `myAddressValue` récupère la valeur de cette adresse . On peut donc s'attendre à obtenir la valeur 874 pour `myAddressPointer` et 1462 pour `myAddressValue`. En quoi est-ce utile ? Parce que nous ne stockons pas seulement des valeurs en mémoire, mais aussi des fonctions et des comportements de méthodes. Par exemple, l'espace mémoire 874 stocke la valeur 1462, mais cette adresse peut également gérer des fonctions permettant de calculer l'intensité du courant en kA. Les pointeurs nous donnent accès à ces fonctionnalités supplémentaires et à l'utilisation des adresses mémoire sans avoir besoin de déclarer une fonction ailleurs dans le code. Un pointeur de fonction typique peut être implémenté comme suit :
void (*funcPtr) (void);
Imaginez utiliser cet outil dans notre automate fini ! Nous pourrions créer un pointeur dynamique pointant vers les différentes fonctions ou états de notre automate, au lieu d'une variable. Avec une seule variable stockant un pointeur qui change dynamiquement, nous pourrions modifier les états de l'automate en fonction des entrées.
Tables de consultation
Passons en revue un autre concept important : les tables de consultation, ou LUT. Les LUT offrent une méthode ordonnée pour stocker des données, dans des structures de base qui contiennent des valeurs prédéfinies. Elles nous seront utiles pour stocker des données dans les valeurs de notre automate fini.
Le principal avantage des LUT est le suivant : si elles sont déclarées statiquement, leurs valeurs sont accessibles via des adresses mémoire, ce qui constitue une méthode d’accès aux valeurs très efficace en C/C++. Vous trouverez ci-dessous une déclaration typique pour une LUT à état fini :

void (*const state_table [MAX_STATES][MAX_EVENTS]) (void) = { action_s1_e1, action_s1_e2 }, /* procédures pour l'état { action_s2_e1, action_s2_e2 }, /* procédures pour l'état { action_s3_e1, action_s3_e2 } /* procédures pour l'état };
Il y a beaucoup d'informations à assimiler, mais ces concepts sont essentiels à la mise en œuvre de notre nouvelle machine à états finis (MEF) performante. Passons maintenant au codage pour que vous puissiez constater la facilité avec laquelle ce type de MEF peut évoluer.
Remarque : Le code complet de l’automate à états finis se trouve ici ; nous l’avons divisé en 5 parties par souci de simplicité.
Codage
Nous allons créer un automate fini simple pour implémenter une routine de clignotement de LED. Vous pourrez ensuite adapter cet exemple à vos besoins. L'automate aura deux états : LED allumée et LED éteinte. La LED s'allumera et s'éteindra chaque seconde. C'est parti !
/* CONFIGURATION DE LA MACHINE À ÉTATS */ /* États valides de la machine à états */ typedef enum { LED_ON, LED_OFF, NUM_STATES } StateType; /* Structure de la table de la machine à états */ typedef struct { StateType State; // Créer le pointeur de fonction void (*function)(void); } StateMachineType;
Dans la première partie, nous implémentons notre table de correspondance (LUT) pour créer des états. Nous utilisons la méthode `enum()` pour attribuer les valeurs 0 et 1 à nos états. Le nombre maximal d'états est fixé à 2, ce qui est cohérent avec notre architecture d'automate fini. Ce type sera nommé `StatedType` afin de pouvoir y faire référence ultérieurement dans notre code.
Ensuite, nous créons une structure pour stocker nos états. Nous déclarons également un pointeur étiqueté fonction, qui sera notre pointeur de mémoire dynamique pour appeler les différents états de l'automate fini.
/* Déclaration initiale de l'état et des fonctions SM */ StateType SmState = LED_ON; void Sm_LED_ON(); void Sm_LED_OFF(); /* Table de correspondance avec les états et les fonctions à exécuter */ StateMachineType StateMachine[] = { {LED_ON, Sm_LED_ON}, {LED_OFF, Sm_LED_OFF} };
Ici, nous créons une instance avec l'état initial LED_ON, puis nous déclarons nos deux états et enfin nous créons notre LUT. Les déclarations d'état et le comportement sont liés dans la LUT, ce qui nous permet d'accéder facilement aux valeurs via entiers des index. Pour accéder à la méthode sm_LED_ON(), par exemple, nous écrirons quelque chose comme StateMachineInstance[0];.
/* Routines de fonctions d'état personnalisées */ void Sm_LED_ON() { // Code de la fonction personnalisée digitalWrite(LED_BUILTIN, HIGH); delay(1000); // Passage à l'état suivant SmState = LED_OFF; } void Sm_LED_OFF() { // Code de la fonction personnalisée digitalWrite(LED_BUILTIN, LOW); delay(1000); // Passage à l'état suivant SmState = LED_ON; }
Dans le code ci-dessus, la logique de nos méthodes est implémentée et ne comprend rien de particulier, hormis la mise à jour du numéro d'état à la fin de chaque fonction.
/* Routine principale de changement d'état */ void Sm_Run(void) { // Vérifie la validité de l'état actuel if (SmState < NUM_STATES) { (*StateMachine[SmState].function) (); } else { // Code d'exception d'erreur Serial.println("[ERREUR] État non valide"); } }
La fonctionSm_Run() est au cœur de notre automate fini. Notez que nous utilisons un pointeur (*) pour extraire l'adresse mémoire de la fonction de notre table de correspondance (LUT), car nous y accéderons dynamiquement lors de l'exécution. Sm_Run() exécutera toujours plusieurs instructions, également appelées événements de l'automate fini, déjà stockées à une adresse mémoire du microcontrôleur.
/* FONCTIONS PRINCIPALES D'ARDUINO */ void setup() { // Insérez votre code d'initialisation ici, exécuté une seule fois : pinMode(LED_BUILTIN, OUTPUT); } void loop() { // Insérez votre code principal ici, exécuté en boucle : Sm_Run(); }
Nos principales fonctions Arduino sont désormais très simples : la boucle infinie s’exécute en permanence avec la routine de changement d’état définie précédemment. Cette fonction gère l’événement qui déclenche et met à jour l’état actuel de l’automate fini.
Conclusions
Dans cette deuxième partie de notre série sur les machines à états finis et les pointeurs C/C++, nous avons passé en revue les principaux inconvénients des routines FSM switch-case et identifié les pointeurs comme une option appropriée et souhaitable pour économiser de la mémoire et augmenter les fonctionnalités du microcontrôleur.
En résumé, voici quelques avantages et inconvénients de l'utilisation de pointeurs dans votre routine de machine à états finis :
Avantages :
- Pour ajouter d'autres états, il suffit de déclarer la nouvelle méthode de transition et de mettre à jour la table de consultation ; la fonction principale restera la même.
- Vous n'avez pas besoin d'exécuter chaque instruction if-else – le pointeur permet au firmware d'accéder à l'ensemble d'instructions souhaité dans la mémoire du microcontrôleur.
- Il s'agit d'une méthode concise et professionnelle pour mettre en œuvre FSM.
Inconvénients :
- Vous avez besoin de plus de mémoire statique pour stocker la table de consultation qui contient les événements de l'automate fini.
